Tidewater Big Data Enthusiasts Presentation Repository
Introduction and background
We are a group of people in the Tidewater area who are interested in exploring, sharing, and understanding Big Data. We have a mixture of people with interests and expertise in various aspects of big data, what it is, how it works, how it affects each of us, and assist people establishing personal networks of friends and colleagues with similar interests.
A collection of things that I hope the group will explore, includes:
- What is "Big Data," how does it affect me, and how am I supplying "Big Data??" Probably include a simple demonstration of using Pig to process Medicare data, and then displaying the results via R.
- Where can I get my hands on some Big Data?? Medicare payments, pharmaceutical payments, census data, ZCATs, etc. Some sort of demo on getting data from these places, how the data has to be munged, what kinds of problems exist with all data sets.
- What kinds of tools are available for processing Big Data?? The world doesn't end at Hadoop or Casandra. There are other tools/applications that might be a better fit.
- How do I visualize all this data?? Getting Big data is fun. Analyzing can be a challenge. When it is all over, how can the data be made real with some sort of visualization techniques.
- What are the challenges with real-time Big Data?? Firstly, what does real-time mean?? Secondly, what kinds of tools are available to handle masses of real-time data.
- How does the "Internet of Things" affect what we call Big Data?? As more and more things (cars, phones, refrigerators, wearable devices) are wired, and more and more data is being collected, how does that affect what we do with Big Data??
As we talk and share ideas, other topics will come up and we will follow them to see where they go.
Come ready to share ideas, experiences, and interest in all things Big Data.
Presentations we have had along the way
2015 Oct. 27: A Presentation on Microsoft Azure and AWS Elastic Cloud Computing (EC2)
Steve Jones will be giving a short presentation on "Big Data in the Cloud: Microsoft Azure." Azure is a cloud computing platform and infrastructure, created by Microsoft, for building, deploying and managing applications and services through a global network of Microsoft-managed and Microsoft partner hosted datacenters.
After that, we'll have a hands-on introduction to Amazon Web Services (AWS) Elastic Cloud Computing (EC2). In order to access the AWS EC2, you have to create an account which includes giving them credit card information. Nothing that we'll do will result in charges on your card. They want the card in case you start using their service a lot, or use it to store data on the "cloud."
As part of the hands-on session we'll be using a virtual machine to run RStudio. RStudio is a GUI front end to R. R is programming environment for statistical computing and graphics and is a mainstay for Big Data analysis.
Low resolution report
High resolution report
2015 Nov. 24: Medicare Payments to the Tidewater Area
In 2013, Medicare was used by about 53 million people. In 2014, there were about 11 million records made available by the Centers for Medicare and Medicaid Services on some of those 53 million people.
At our next meeting, we will explore some of these data records. We'll use a Hadoop/Hive back end to provide raw data to an R script, resulting in a PDF report showing the financial impact of selected procedures in various ZIP codes in the Tidewater area.
Bring your laptop, or smart phone. This is a hands on Big Data exploration in the wild!!
The final report.
2015 Dec. 22: No meet-up. Too close to Christmas
2016 Jan. 26: Tools and techniques to visualize Big Data
It is very difficult to come to grips with large data sets. Even the relatively small Medicare data set that we looked at in November (9.3 million records) can be overwhelming. We'll take a look at how to visualize large data sets (and have some hands-on activity) when we take ideas from Nethan Yau's book "Data Points: Visualization That Means Something."
Report
2016 Feb. 23: Publicly Available Sources of Big Data
We constantly hear that we are awash in Big Data. We create Big Data. We are a part of Big Data. Everything that we do is somehow a part of Big Data.
What we don't hear is how can I get my hands on some of this Big Data stuff. Where is it? What does it look like? How can I get my hands dirty playing with Big Data?
We will take a look at Big Data sources. The kinds of Big Data sources that are available. What does Big Data look like. And, how can I find more Big Data.
Report
Report about looking at ExIF data
Report on how many Vs are there in Big Data
A dump of selected Tweets
2016 Mar. 22: Big Data Variety, or I've got your number
Doug Laney has been credited with identifying the original Big Data 3Vs: volume, velocity, and variety. He characterized these as being part of the 3D Data Management problem that was "breaking" traditional relational database management systems. His 3Vs caught on and now there are more Vs than you might care to count. This meet-up we'll be talking about one of his initial Vs: variety.
We'll focus on three simple types of numbers: phone numbers, credit card numbers, and Social Security numbers. We'll look at how many different ways these simple numbers can and are requested on the Internet, and then we'll extend those ideas to tougher problems like street addresses.
Report
2016 Apr. 26: Big Data Velocity, or Where and Why is this Data Coming so Fast
Doug Laney has been credited with identifying the original Big Data 3Vs: volume, velocity, and variety. His 3Vs caught on and now there are more Vs than you might care to count. This meet-up we'll be talking about one of his initial Vs: velocity.
We'll start off with velocity in Laney's context, and then look at if from a current and more recent point of view. We'll talk about tweets, Twitter, and some of the things that you can learn about tweeters. We'll take a peek at the a very small portion of the "tweeterverse" and then go live to see what is out there. There might be more to a tweet than meets the eye.
Report
Real time tweet sample
2016 May 24: Using Big Data to Get Us from Where We Think We Are to Where We Might Want to Go
We'll explore some of the Internet Movie Data Base of over 6,000,000 records. We try and from where we thought we were (starting with Levenshtein's algorithm) to where we might want to be using a PosrgreSQL relational database. Levenshtein's algorithm is behind many of today's spell checker functions. We'll use it to make sense of some misspelled actors, and use those actors to make recommendations of movies that are sort of like the ones we already like. And we'll do all this live
We'll talk about the PostgresQL a little, then how we'll use the Internet Movie Database (IMDb) as a source of interesting data. Data that is interesting in it's own right, and data that we can ask interesting questions about. After we've talked about the prototype recommender system, we'll test it live.
Report
Live run
2016 June 28: Using Big Data to Connect the Dots from One Place to Another
We'll explore the world of graphical databases. Databases that don't have tables, or rows, or columns, and don't use the structured query language (SQL). These are databases are behind things like Google Maps, finding board of director relationships between companies, first level technical support questions, and disease diagnosis.
We'll use our friend, the Internet Movie Database and the Neo4J software to play the "Six Degrees of Kevin Bacon" game, to find things like the actor (or actress) who has appeared in the most movies, and to find the movie that was most influential in cinematographic arts. These are the same questions that are used to map out companies and terrorist cells.
Presentation
Report
Live run of Internet mapping
2016 July 26: Using Big Data Tools when there are Holes in the Data
We'll explore the world of columnar databases. Databases that have rows and columns, but the intersection of a row and a column can have 0 or more values. The values can be versioned, timestamped for automatic deletion, and other neat features. We'll look at HBase (one of many databases built on top of Hadoop), to explore some of the data in the Internet Movie Database. HBase is used by Adobe, LinkedIn, Netflix, Spotify, and others.
Presentation
Report
2016 Aug 30: Using Big Data to look at Political Party Platforms
The political season is upon us. All of the major parties have declared their platforms and how they will change the country for the better.
We'll use some Big Data textual analysis tools and techniques to look at the platforms from the five major parties. Sentiment analysis will quantify how positive or negative a platform is. Vocabulary analysis will tell us what grade level the platform is speaking to. We'll look at how vocabulary, sentiment, and state population demographics could be combined to predict how a state might vote.
Lots of balls in the air. It will be interesting to see how they land.
Report
Exploration with Text Mining
Presentation
2016 Sep 27: Where did we come from? Where might we go?
The US population is constantly moving. From the East westward. From the North southward, and then back. Is there a way to visualize these movements over time?
We'll dive into the US Census databases looking for population density data. We expect that we'll easily find data for recent censuses, earlier ones may be a challenge. The data should have at least these attributes: location, magnitude, and time. It may also have these: age, gender, race, or type of household. We'll see what data is available, and how decide on how to visualize the changes over time.
Come join use while we swim through this data lake.
Report
Presentation
2016 Oct 25: Big Data Potential of GDELT
The Global Database of Events, Language, and Tone (GDELT) is the largest, most comprehensive, and highest resolution open database of human society ever created. Creating a platform that monitors the world's news media from nearly every corner of every country in print, broadcast, and web formats, in over 100 languages, every moment of every day and that stretches back to January 1, 1979 through present day, with daily updates. The GDELT has created a database of a quarter billion georeferenced records covering the entire world over 30 years.
We'll take a peek into GDELT and see what we can do with a standalone application, and also what can be done using Google's Big Table technology.
Report
Presentation
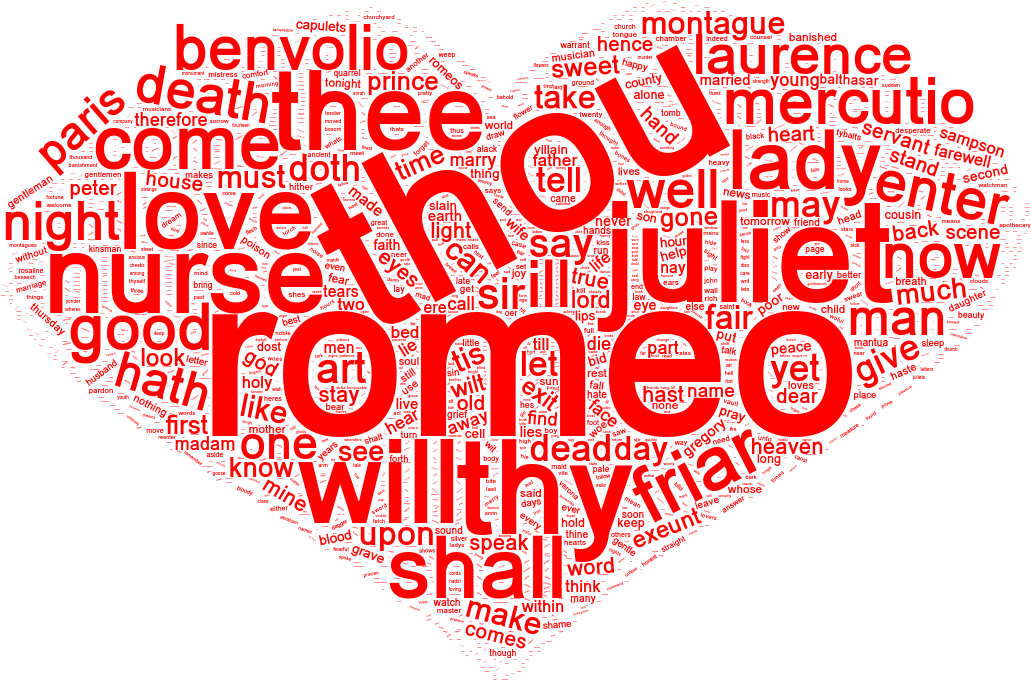
2016 Nov 3: Creating Shaped Wordclouds Using R
The R "wordcloud" library provides an easy way to create an image showing how often a word (or tag) appears in a corpus.

In a word cloud, the size of a word indicates how often that word appears. Word cloud words can be colored as well. While word clouds are easy to create, often the clouds could be shaped differently to create a more lasting and profound impression.
Report
2016 Nov 22: Connecting the Dots in Wikipedia
Dirk Gently's code is that everything is connected. This the basis of his holistic detective agency, and is his life's guiding principle. We will take Dirk's principal idea and apply it to Wikipedia. We'll explore a portion of Wikipedia and see how many pages/links separate a specific page from another (in graph theory this is called the shortest path, Stanley Milgram made this idea popular with his "Small-World" paper, and many people have played the "Six Degrees of Kevin Bacon" game). We'll also look at the average number of links between pages.
Along the way, we'll look at words that are common between the pages, the educational level of the pages, and other things if we have time. For fun; we'll use SQL and non-SQL databases to manage the exploration process and keep track of the results.
Report
Presentation
2017 Jan 29: Will you live see your program end?
In the world of Computer Science, there are all sorts of problems. Problems that can be easily stated, but not so easily answered. Problems for which there is a single, optimal answer that can be arrived at in a reasonable length of time. Problems for which an optimal answer can not be arrived at using the world's fastest computers before the universe comes to an end. Some of these problems are simple, and some are complex. We will be taking a look at some of these problems in general, and then look how some can be attacked using R.
Report
2017 Mar 1: Weather or Not You Believe It
Weather is everywhere. Sounds trite to say that, but it is true and a lot of real-time data is available for free, just for the downloading. We will look at semi-realtime weather data available from the National Oceanic and Atmospheric Administration (NOAA) collected and consolidated from over 25000 uniquely identified United States Air Force (USAF), and 3000 Weather-Bureau-Army-Navy (WBAN) weather stations world wide. Some weather stations have both USAF and WBAN identifier, while others may have only one. During this exploration, we will be creating "heat maps"" of temperature for the states of Virginia, and North and South Carolina. These states were chosen because of local interest. The attached R script can be modified to display the same data for any collection of the US states.
Report
2017 Apr 1: In Search of the Royal Mail Ship (RMS) Titanic
The sinking of the Royal Mail Ship (RMS) Titanic on her maiden voyage is a source of constant mystery and romance. Now after more than a century, there are still unanswered questions about the disaster that made her a part of the English lexicon. Perhaps the simplest question is: how many people (passengers and crew) were on board when she sank, and how many survived? Surprisingly, there is no definitive answer to this most simple of questions. Neither from the White Star Line (her owner), nor from the British Wreck Commissioner assigned to inquiry into her sinking. In this report, we will enumerate some of the disparate sources, and look at some data that has made its way into the R programming language.
Report
2017 Nov 5: Using Crime Statistics to Recommend Police Precinct Locations
Cities and governments are responsible for the safety and security of their citizens. They are also responsible to use their money responsibly. From a city planner's perspective, one question that combines both of these needs is: where should new police precincts be located? This simply stated problem is complicated because some police precincts are already built and operational, so the placement of new precincts has to keep the existing ones in mind.
Report
2019 Nov 17: Data Science Approach to Retirement Planning
Retirement planning is a serious topic and should not be undertaken lightly. That said; I am not a financial planner, nor do I play one on television. I do like to play with numbers, and so I undertook to see how retirement planning could be viewed using ideas from Data Science in order to better understand the goals of trained, official, and professional financial planners. This report documents how I worked to answer the question: what will our financial life be like after retirement?
Thank you to Lane Cartledge and Tapan Amin for getting me off "top dead center" to write this report. And to Mary, who allowed me the time necessary to tease apart the ideas we were taught, and to organize them in a way that made sense for us.
The results of the spreadsheet embedded in the report could be compared to those mandated by the Setting Every Community Up for Retirement Enhancement (SECURE) Act. Be sure to always consult a trained financial advisor.
Report
2020 Feb 25: Changes in Watertable Levels Due to Tidal Influences
Several years ago (unfortunately I can't point to a specific source), I heard that water table level was affected by the same tidal forces that create ocean and sea tides. It seemed a little odd to me at the time, and didn't resurface until shortly before the time of this report. I was determined to see if the local water table rose and fell in accordance with local tides.
Report
2020 Apr 4: Network Measures of the Code of Virginia
We explore the Code of Virginia as a network graph, using citation analysis techniques. During the exploration, we report the size and connectiveness of the graph, how many of the graph nodes are self referential, and the graph's longest path. We uncover some "hidden" problems with the data (including references to notes that do not appear to be part of the publicly available record), and inconsistencies in format that challenges machine driven exploration.
This report looks at the Code of Virginia as a HTML linked structure. We do not make any statements about the relative merits, or relationships implied by the HTML linkages, just that the HTML pages are connected in someway via HTML link tags.
Report
2020 May 10: Exploration into Exif Data
We explore how Exchangeable image file (Exif) data can be used to create a photo album using the Global Positioning System (GPS) temporal and positional data automatically embedded by many smart phones into Joint Photographic Experts Group (JPEG) images. We look at the quality of the embedded data, how the data is used "behind the scenes" by image browsers to "correct" things, and discover operating system limitations that affect how images can be processed. The end result being a web page JavaScript enabled clickable geographic oriented web page.
Report
2020 May 24: Finding a Face in a Sea of Faces
Often times when a group gets together, for whatever reason, there will be a group picture at the end to commemorate the good times had by all. If this "sea of faces" gets published, in hard or soft copy, there may be a one or two line caption giving the name of the group and perhaps where and when the image was created. Six months or a year later, the image has only marginal value to the people who were there, and almost no value to those who were not there, because it is just a sea of faces.
We are interested in finding a low cost (very little human time) method of providing a way to add value to the soft copy of the image, so that the image will have greater value later. We have developed a Python script that uses a Haar facial detection cascade to create a clickable HTML image map. The image map can be incorporated into other HTML pages to support a dynamic and valuable web experience.
The Python script, Haar file, and sample images are included in this report.
Report
2020 July 14: Where, oh where has the little plane gone?
We look at what information can be found starting with an aircraft tail number, an airline, and a starting departure airport. We construct a PostGreSQL database to hold the data as long term persistent storage, and use Bureau of Transportation Statistics (BTS) departure data to identify where a tail number is going to next.
After we have queried the BTS database to extract all of the airports that a tail number has departed from, we analyze the data in various ways to: 1) identify where the tail number has departed from, 2) what day of the week the tail number departed on, 3) what hour of the day the tail number took off, 4) where the domestic departure airport is located, 5) how long the airport has been in service, and 6) has the airport moved in its lifetime.
The Python script and airport location file are included in this report.
Report
2021 June 16: Playing with Dice
We will be exploring how the number of dice, and their pips interact by focusing on:
- how the "expected value" for a particular dice and pip combination changes when either the number of dice, or the number of pips change,
- how the distribution of pip summations is affected by the number of dice and pips, and
- how different implementations of dice and pip interaction tools affect our ability to explore this problem domain.
We'll do this by creating a tool to help us explore this domain, then look at the classic 2-dice 6-pip combination world. After developing a set of equations for this world," we'll use them to help us explore larger worlds where the number of dice remains constant, but the pips change, then where the pips remain constant, but the dice change.
All source code, and an interactive 3D web page are included in this report.
Report
2021 July 22: Calendar Dice
We will be exploring how 2 six-sided die can be used to show the date in a perpetual calendar. We will develop a C++ program that will locate all valid dice configurations out of a potential 1012 combinations in less that 1 minute.
Report
2021 November 4: Exploring the United Kingdom Department for Transport Ministry of Transport Anonymised Safety, Roadworthiness Test Results
The UK Ministry of Transport (MOT) is required to test cars and other light vehicles at least once a year to ensure they comply with the current road worthiness and environmental requirements. The anonymised results of these nation wide tests are made available to the public. This report details an exploration into the 2021 test results.
Report
2024 July 16: Exploring Kaprekar’s Constant
We explore the world hinted at by Kaprekar’s routine to manipulate four digit decimal numbers. Kaprekar’s routine takes a number, manipulates the digits, subtracts two newly created values, and repeats these steps until the value 6174 is computed. Once 6174 is computed, the routine is "stuck" at this value and will never change. The simplicity of the routine cries for computerization to determine if all four digit decimal numbers get stuck at 6174, or not.
Report
2024 December 13: To Honor Mary Hugh Dotson Cartledge
This is purely personal to honor my wife.
A link to her obituary at the Cremation Society of Virginia https://vacremationsociety.com/obituary/mary-dotson-cartledge/
A link to a scholarship at Virginia Commonwealth University for first generation Master of Social Work students https://blogs.vcu.edu/social-work/2023/09/12/the-power-of-love-endowed-scholarship-honors-mary-cartledge-m-s-w-78-sw-son/
A link to a tribute to Mary https://drive.google.com/file/d/1VPIhzBt4vPVuRKdLkM7EqCTSwY839gFV/view
The tribute is also available here.
A write-up about her and her scholarship in the VCU Magazine for Alumni and Friends https://magazine.vcu.edu/2023-fall/for-love-of-one-and-yall/
A write-up about where some of her ashes have been spread is here.
2025 October 31: Exploring Baby Names Using Social Security Administration (SSA) Number Applications
We examine Social Security Number (SSN) applications as provided by the Social Security Administration (SSA) to see how the self declared first name and gender of the applicant changes over time. The source data includes the first name of the applicant, their gender, and the number of times that name and gender combination occurs per year. We suspect that names tend to be gender specific, but may not be absolutely specific.
We look at the absolute number of applications per year, changes in absolute numbers as a percentage from the previous year, possible economic influences (recessions and depressions) on SSN applications, and how selected names wax and wane over time.
Report